Compare Files Tool
The built-in Compare Files tool can be used to compare files or XML file fragments. The tool provides a mechanism for comparing two files or fragments, as well as the mechanism for a three-way comparison. The utility is available from the menu or can be opened as a stand-alone application from the Oxygen XML installation folder (diffFiles.exe). The utility is available as a stand-alone application and can be opened by running its executable file (diffFiles.exe) from the Syncro SVN Client installation folder. The functionality of this standalone tool is similar to the comparison feature in the Syncro SVN client with a few slight differences in the interface and some options.
Two-Way Comparisons
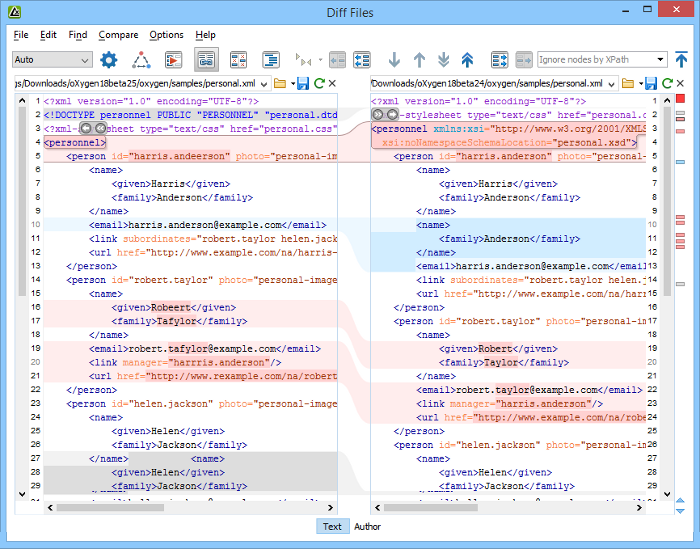
The Compare Files tool can be used to compare the differences between two files or XML fragments.
-
Open a file in the left panel and the file you want to compare it to in the right panel.
Step Result: The selected files are opened in the two side-by-side editors. A text editing mode is used to offer a better view of the differences.
- To highlight the differences between the two files, click the
 Perform File Differencing button from
the toolbar.
Perform File Differencing button from
the toolbar. - You can use the drop-down menu on the left side of the toolbar to change the algorithm for the operation.
- You can also use the
 Diff
Options button to access the Files Comparison
preferences page where you can choose to ignore certain types of markup and configure
various options.
Diff
Options button to access the Files Comparison
preferences page where you can choose to ignore certain types of markup and configure
various options. - If you are comparing XML documents using the XML Fast or XML Accurate algorithms, you can enter an XPath 2.0 expression in the Ignore nodes by XPath text field to ignore certain nodes from the comparison.

- Pink - Identifies modifications on either side.
- Gray - Identifies an addition of a node in the left side (your outgoing changes).
- Blue - Identifies an addition of a node in the right side (incoming changes).
- Lighter Shade - Identifies blocks of changes that can be merged in their entirety.
- Darker Shade - Identifies specific changes within the blocks that can be merged more precisely.
 Close () button,
before pasting the fragments. Other notes for pasting fragments:
Close () button,
before pasting the fragments. Other notes for pasting fragments:- As long as the fragment is more than 10 characters, the application will attempt to automatically detect the content type. It can detect the following types: XML, DTD, CSS, JSON, and Markdown (if it starts with #). If one of those content types is detected, the fragments will be displayed with syntax highlights.
- If you save modified fragments, a dialog box opens that allows you to save the changes as a new document.
-
Syntax Aware - Computes differences for known file types or fragments. This algorithm splits the files or fragments into sequences of tokens and computes the differences between them. The meaning of a token depends on the type of compared files or fragments.
Known file types include those listed in the New dialog box, such as XML file types (XSLT files, XSL-FO files, XSD files, RNG files, NVDL files, etc.), XQuery file types (.xquery, .xq, .xqy, .xqm extensions), DTD file types (.dtd, .ent, .mod extensions), TEXT file type (.txt extension), or PHP file type (.php extension).
For example:- When comparing XML files or fragments, a token can be one of the following:
- The name of an XML tag
- The < character
- The /> sequence of characters
- The name of an attribute inside an XML tag
- The = sign
- The " character
- An attribute value
- The text string between the start tag and the end tag (a text node that is a child of the XML element corresponding to the XML tag that encloses the text string)
- When comparing plain text, a token can be any continuous sequence of characters or any continuous sequence of whitespaces, including a new line character.
- When comparing XML files or fragments, a token can be one of the following:
Three-Way Comparisons
- Visualize and merge content that was modified by you and another member of your team.
- Marks differences correctly even when the document structure is rearranged.
- Allows you to merge XML-relevant modifications.
-
Open a file in the left panel and the file you want to compare it to in the right panel.
Step Result: The selected files are opened in the two side-by-side editors. A text editing mode is used to offer a better view of the differences.
- Click the
 Three-Way
Comparison button on the toolbar and select the base (original) file in
the Base field.
Three-Way
Comparison button on the toolbar and select the base (original) file in
the Base field. - To highlight the differences, click the Perform File Differencing button on
the toolbar.
- You can use the drop-down menu on the left side of the toolbar to change the algorithm for the operation.
- You can also use the Diff
Options button to access the Files Comparison
preferences page where you can choose to ignore certain types of markup and configure
various options.

Second-Level Comparisons
For both two-way and three-way comparisons, Oxygen XML automatically performs a second-level comparison for the Lines, XML Fast, and XML Accurate algorithms. After the first comparison is finished, the second-level comparison for the Lines algorithm is processed on text nodes using a word level comparison, meaning that it looks for identical words. For the XML Fast and XML Accurate algorithms, the second-level comparison is processed using a syntax-aware comparison, meaning that it looks for identical tokens. This second-level comparison makes it easier to spot precise differences and you can merge or reject the precise modifications.

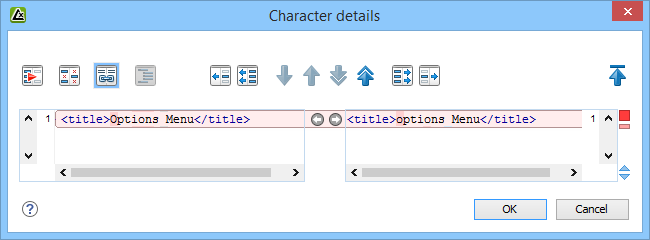
To do a word level comparison, select Show word level details from the contextual menu or Compare menu.
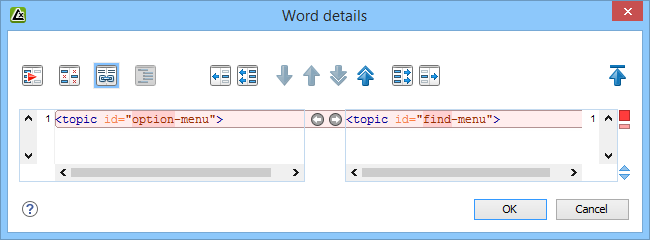
To do a character level comparison, select Show Character Level details from the contextual menu or Compare menu.
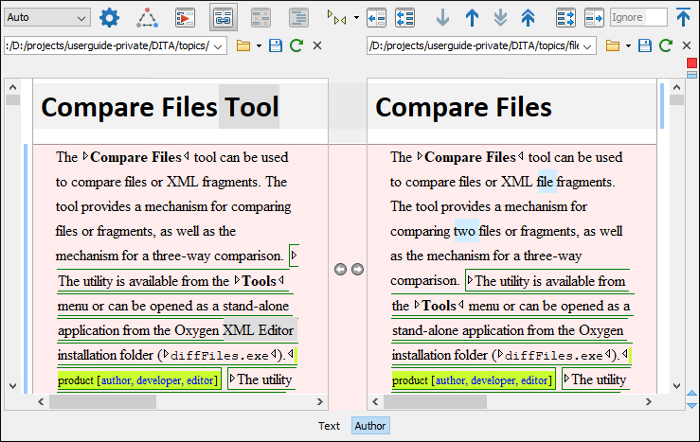
Author Visual Mode
This visual mode includes unique features such as a  Tags Display Mode drop-down
button on the toolbar that allows you to select the amount of tags to display in
this visual mode. This mode also presents differences that were made using the
Track Changes feature (although the Track
Changes feature is not available in the comparison tool).
Tags Display Mode drop-down
button on the toolbar that allows you to select the amount of tags to display in
this visual mode. This mode also presents differences that were made using the
Track Changes feature (although the Track
Changes feature is not available in the comparison tool).
Author Mode Algorithms
Author Mode Second-Level Comparisons
The visual Author comparison mode automatically performs a second-level comparison for the XML Fast and XML Accurate algorithms. After the first comparison is finished, the second-level comparisons is processed on text nodes using a word-level comparison, meaning that it looks for identical words. This second-level comparison makes it easier to spot precise differences and you can merge or reject the precise modifications.