Page 1 of 1
Searching Chinese contents doesn't work
Posted: Mon Feb 24, 2020 7:38 am
by catherine
Hi,
I find that the searching engine for Chinese is not good.
Sometimes, I cannot search I want in the webhelp.
Even I search a topic title,no searching result is displayed.
Any configuration that I should do to make the searching engine work better for Chinese contents?
Re: Searching Chinese contents doesn't work
Posted: Mon Feb 24, 2020 5:00 pm
by Costin
Hi Catherine,
We need you to provide an example of what you tried to search and did not return any results.
Also, it would be great if you could provide us access to a WebHelp output of yours, that reproduces the issue (you could provide the output or a link to a hosted output on our official support email:
support@oxygenxml.com).
Best Regards,
Costin
Re: Searching Chinese contents doesn't work
Posted: Tue Jul 07, 2020 6:29 am
by catherine
Hi, do you have plan to improve the searching function.
The searching rule for Chinese contents has a bad user experience.
No user will know the searching rule that they need to add space between a chinese word.
Or, what else we can do ourselves to solve this problem?
Re: Searching Chinese contents doesn't work
Posted: Tue Jul 07, 2020 2:36 pm
by cosmin_andrei
Hi Catherine,
We do not have short term plans about this but I added your feedback to an opened issue and we'll update this forum thread when we implement such a feature.
Re: Searching Chinese contents doesn't work
Posted: Fri Jul 10, 2020 11:41 am
by catherine
Hi, Cosmin
Thanks for your reply.
Best Regards,
Catherine
Re: Searching Chinese contents doesn't work
Posted: Mon Mar 22, 2021 9:59 pm
by cparrott
Hi Cosmin,
It was brought to my attention that the Chinese search for the documentation I work on does not work, which is how I came to this thread. The responsive output I'm writing for is part of a software package so I can't link to it here but I can't get the Chinese search to work without adding spaces between the characters, which none of my users in China would know to do.
I'm guessing from this thread that this is just a bug and there's not a way to fix it, but I just wanted to echo my support of improving the Chinese search function. Thank you very much!
Claire
Re: Searching Chinese contents doesn't work
Posted: Tue Nov 02, 2021 7:48 pm
by kmckenna7
Has anyone else experienced issues? Chinese search seems to have issues with full headings, not partial, for me... not working 100%. not sure why.
Re: Searching Chinese contents doesn't work
Posted: Wed Nov 03, 2021 4:01 pm
by cosmin_andrei
Hello,
In order to investigate this issue on our side it would be very useful to send us a minimal valid sample project on which you reproduce the problem.
Re: Searching Chinese contents doesn't work
Posted: Tue Dec 14, 2021 8:50 am
by kmckenna7
Chinese search is still having issues in 2021!
Re: Searching Chinese contents doesn't work
Posted: Fri Oct 27, 2023 2:56 pm
by Radu
Hi,
I'm interested in investigating the Chinese search problem in the Oxygen WebHelp to possibly improve it.
Does anybody on this thread want to provide us with small samples showing how it works/should work and maybe give us some feedback along the way? If so you can email us at "
support@oxygenxml.com".
Regards,
Radu
Re: Searching Chinese contents doesn't work
Posted: Mon Oct 30, 2023 12:29 pm
by galanohan
Hi Radu,
I asked a similar question four months ago, Costin gave me a javascript template as a solution, then I modified that script to make it happen.
See here:
post72152.html#p72152
The logic is quite simple: for every Chinese input in the search bar, split the string and separate every 2 chars by spaces. Because after hundreds of webhelp transformation, I can see that searching Chinese content doesn't work when the number of characters exceed 2. For example, "AB" or "A" is ok as search words, but ABC, ABCD, ABCDE would fail.
So the script is as follows:
var executed = false;
$( document ).ready(function() {
$("#searchForm").on("submit", (e) => {
// WebHelps triggers the submit event handler multiple times.
if(!executed) { // We make sure that we execute it only one time.
e.stopPropagation();
var userQuery = $('#textToSearch').val();
if (userQuery.trim() === '') {
e.preventDefault();
return false;
}
if (!/^[a-zA-Z]+$/.test(userQuery)) {
userQuery = userQuery.replace(/[\u4e00-\u9fa5]{2}/g, '$& '); // if the input isn't english characters, split every given Chinese input (string) by separating every two Chinese chars by spaces.
}
// userQuery = userQuery.replace(/[\u4e00-\u9fa5]{2}/g, '$& '); // split every given Chinese input by separating every two Chinese characters by spaces.
//userQuery = userQuery.replace(/[\u4e00-\u9fa5]/g, '$& '); // split every given Chinese input by separating every Chinese character by spaces.
$('#textToSearch').val(userQuery);
executed = true;
}
});
});
In the scripts above, starting from line 13, there are three options for splitting a given Chinese string in search bar. The first one, which I'm using now, detects the input string to determine if it's Chinese or latin languages, splits the string into an array of word groups, for example, converts "ABCDEFG" into "AB CD EF G" as search keywords, returns the result to the search form.
The next two options functions in the same way but only detects if the string is Chinese and will carry out only when the string contains Chinese. See the comments after each line.
The js file is specified in an html file:
<!DOCTYPE html>
<html>
<script src="${oxygen-webhelp-template-dir}/js/custom.js" defer="defer"></script>
</html>
And in the publishing template, js file is included in fileset area, and the html file that calls the js file is specified in html-fragment area.
<html-fragments>
<fragment file="fragments/js.html" placeholder="webhelp.fragment.after.body"/>
<!--DO NOT DELETE THIS LINE!-->
</html-fragments>
<resources>
<css file="styles.css"/>
<fileset>
<include name="resources/**/*"/>
<exclude name="resources/**/*.svn"/>
<exclude name="resources/**/*.git"/>
<include name="js/**"/>
</fileset>
</resources>
Here's the publishing package I'm using. Thanks Costin for the great answer, and I'm happy to share the solution other writes struggling with similar issues.
----------------------
The scripts above is quite simple and function perfectly, except that the splitted strings, or let's say, group of words are also displayed in the search bar on a search result page. For example, for a given string containing Chinese characters ABCDEFG, when the search results are returned, "AB CD EF G" as visible in the search bar. It would be great to have a script or two to join these word groups into one piece in the search bar after returning the search results.
Re: Searching Chinese contents doesn't work
Posted: Mon Oct 30, 2023 2:35 pm
by Radu
Hi Galanohan,
Thanks for jumping in, looking at the thread you indicated it's mostly for using feedback-based search in the webhelp output. I'm mostly interested in making this work with the offline search engine.
Out of curiosity what xml:lang attribute value have you set on your DITA Map and topics? Did you set "zh" or "zh-CN"?
Regards,
Radu
Re: Searching Chinese contents doesn't work
Posted: Tue Oct 31, 2023 5:13 am
by galanohan
Hi Radu,
The scripts above was created when I was using the trial version of oxygen feedback in September. Actually it was because of the failure of searching Chinese keywords always returns nothing in webhelp transformation (offline, local build), then I asked a similar question, then Alin, I think, suggested using oxygen feedback as an alternative, however, oxygen feedback back in September or August had very limited support for searching Chinese content. Although there's a bug fix for the issue in late September, that bug fix caused another issue that when setting the search language as Chinese, English or latin characters cannot be searched. When deploying the webhelp package to the file server of my company, the search engine of feedback overrides the offline search engine came with the webhelp transformation. So I ended the trial of oxygen feedback and returned to the offline search engine with the scripts above.
So, yes, the scripts above work with offline search engine.
As for the xml:lang attribute, I set it at the root level, the bookmap. When I need a quick test for certain chapters, I would set the xml:lang at the map level with value as zh-CN (simplified Chinese). This would guarantee that the built-in prompt message like Notes, About this task, Before you begin can be localized as they were predefined when xml:lang is set to certain language code.
It seems that even though I don't set the xml:lang for maps or topics, the scripts above remain effective as I expected, it's just that prompts like Notes, Warning, Before you Begin, About this task, etc. are displayed in English again.
Re: Searching Chinese contents doesn't work
Posted: Tue Oct 31, 2023 8:44 am
by Radu
Hi,
Actually it was because of the failure of searching Chinese keywords always returns nothing in webhelp transformation (offline, local build)
....
As for the xml:lang attribute, I set it at the root level, the bookmap. When I need a quick test for certain chapters, I would set the xml:lang at the map level with value as zh-CN (simplified Chinese).
According to the DITA specification the root attribute myst be set on all maps and topics. One problem I recently encountered and fixed in our internal code is that when the xml:lang is set to "zh-CN" instead of plain "zh" the WebHelp offline search does not work at all.
So setting the xml:lang to plain "zh" in all maps and topics should even now with the Oxygen 25.1 or 26 publishing engine produce webhelp which is searchable offline.
Regards,
Radu
Re: Searching Chinese contents doesn't work
Posted: Tue Oct 31, 2023 12:44 pm
by galanohan
In the definition that oxygen xml editor follows, zh refers to Chinese written languages including Simplified Chinese used by Chinese in China mainland, Singapore, Malaysia, and certain other regions/countries, Traditional Chinese used in China Taiwan, Hongkong, Macau, and other regions.
zh-CN refers to Simplified Chinese which is the first case of "zh", or equivalent to "zh-Hans" (in which s stands for simplified) defined by IANA (
https://www.iana.org/assignments/langua ... g-registry to my surprise, there are 26 zh- variants in use as of today).
Then I took two tests just now. For the first one, I kept xml:lang="zh-CN" in the maps and topics, and generated a offline webhelp package, in the search bar, I typed in two search words of the same meaning, in fact, the same word but in Simplified Chinese and Traditional Chinese respectively. For the simplified Chinese input, the search is ok. For the traditonal Chinese input, none was returned.
Then I had a batch replace from "zh-CN" to "zh" for all xml-lang tags in maps and topics, generated the offline webhelp package again, and did the same search. The result was the same, Simplified Chinese inputs in search worked well, while Traditional Chinese returned nothing.
The xml:lang tag is required for maps but for topics nested in a particular map, the tag is not mandatory to have in a map transformation, unless the transformation takes place to specific .dita topics. So in a context of book publishing where a books contains multiple maps as chapters, only the maps and bookmap need to have xml:lang tags, topics as the children of maps inherit the settings at the map level.
Then I took another boring but interesting test with two parts:
Part 1:
1. Added a paragraph containing Traditional Chinese (let's say "AB") in a topic.
2. Set the xml:lang as zh.
3. Generate a webhelp, and search the words (let's say "AB") from the sentence added in step1 with Simplified Chinese input and Traditional Chinese input.
Test result:
- When the input is in Simplified Chinese, "AB" cannot be searched.
- When the input is in Traditional Chinese, "AB" is returned in search results.
Part 2:
1. Added a paragraph containing Traditional Chinese (let's say "AB") in a topic.
2. Set the xml:lang as zh-CN.
3. Generate a webhelp, and search the words (let's say "AB") from the sentence added in step1 with Simplified Chinese input and Traditional Chinese input.
Test result: Same as Part 1.
Conclusion:
1. Traditional Chinese and Simplified Chinese inputs are not interchangeable during a search query.
2. Either xml-lang = zh or zh-CN, search results in webhelp depend on search inputs.
-------------------------
Final conclusion: Rebuild the Tower of Babel.
Re: Searching Chinese contents doesn't work
Posted: Wed Nov 08, 2023 10:01 am
by Radu
Hi,
Thanks for your experiments.
About this:
The xml:lang tag is required for maps but for topics nested in a particular map, the tag is not mandatory to have in a map transformation, unless the transformation takes place to specific .dita topics. So in a context of book publishing where a books contains multiple maps as chapters, only the maps and bookmap need to have xml:lang tags, topics as the children of maps inherit the settings at the map level.
Can you tell me on what you base your assumptions?
The DITA 1.3 specification states:
https://www.oxygenxml.com/dita/1.3/spec ... llang.html
If the root element of a map or a top-level topic has no value for the@xml:lang attribute , a processor SHOULD assume a default value.
In my opinion, especially when publishing to web-based outputs the xml:lang attribute
must be placed in all topics and maps on the root element because each topic produces its own HTML equivalent and it is not inherited from the root DITA Map.
About your experiments, I'm mostly interested in simplified Chinese I guess. Maybe we could focus on using the same DITA Project in order to test and discuss on the same set of resources.
I'm using for tests this publicly accessible DITA Map I translated to Chinese using a combination of Google Translate and ChatGPT:
https://github.com/oxygenxml-incubator/ ... -unescaped
If I publish it for example to WebHelp Responsive and use the offline index, I search for:
I will find no result.
If I change the xml:lang in all topics and maps from "xml:lang="zh-CN"" to "xml:lang="zh"" then republish to WebHelp, my search for the same content should find a match in a topic.
This is why I mentioned that discrepancy between using "zh" and "zh-CN" as an xml:lang attribute that I want to fix.
Regards,
Radu
Re: Searching Chinese contents doesn't work
Posted: Wed Nov 08, 2023 1:32 pm
by galanohan
Hi Radu,
In fact, I enabled DITA 2.0 spec support in both oxygen v25.1 and v26.
I forked a repo from the one you posted above and did some tests:
Test 1.
No modification to xml:lang attributes for files in both /flowers-ch/ and /flowers-ch-references-unescaped/ folders. Test results: "您需要适当地为植物提供营养" can be searched and returned as the first result.
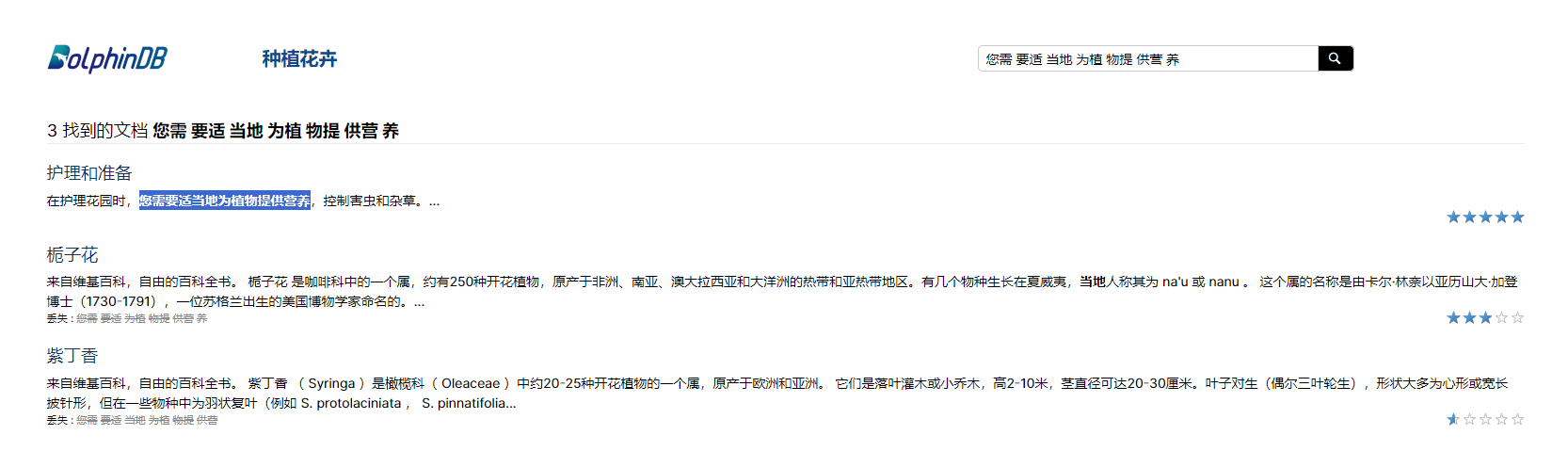
- image.png (52.52 KiB) Viewed 1170 times
Test 2. I removed all xml:lang attributes from all topics except for the one for the map. In this test, I used
xml:lang="zh-CN". Test results are the same as Test 1.
Test3. Almost the same as Test 2 but
xml:lang value is set as "zh" . Similarly to Test 1, the same keyword string can be searched and is returned as the first result. But only two results in total are returned in total, this happens to topics and maps in both folders, /flower-ch/ and /flower-ch-references-unescaped/.
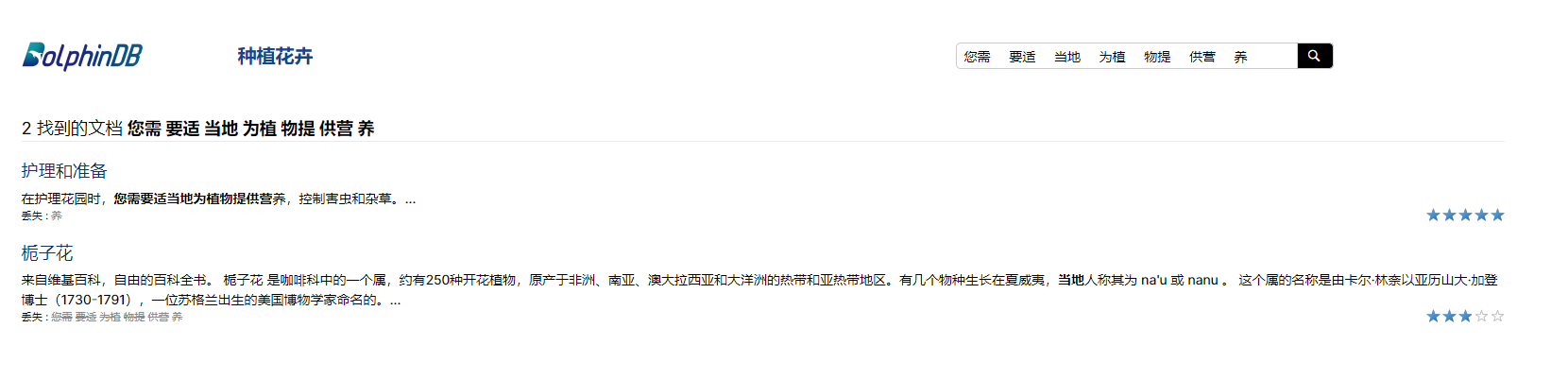
- image.png (36.55 KiB) Viewed 1170 times
Tests were completed with oxygen v26, JRE: Eclipse Adoptium\jre-21.0.0.35-hotspot.
Modified topics and maps, as well as output files can be found here:
https://github.com/Baiamanov/flowers-dita-chinese .
Note: the very last commit to this fork repo contains the modifications and outputs of Test 3.
Re: Searching Chinese contents doesn't work
Posted: Thu Nov 09, 2023 11:34 am
by Radu
Hi,
Your attempts work probably because you are publishing to WebHelp using your own WebHelp customization template containing the custom javascript file which splits the searched string every two characters.
My interest is in making the search work with the stock/predefined "DITA Map WebHelp Responsive" transformation without any extra Javascript workarounds added to a publishing template. And if you try that "DITA Map WebHelp Responsive" builtin transformation on the sample project, you will see that searching works with it when using "xml:lang="zh"" in the DITA Map and does not work when using "xml:lang="zh-CN"" in the DITA Map. And this is what I said I wanted to fix.
Regards,
Radu
Re: Searching Chinese contents doesn't work
Posted: Mon Nov 13, 2023 4:45 am
by galanohan
Hi Radu,
Yes, with the default built-in webhelp transformation scenario, search is available only when xml:lang is set as zh at the map level (it's fine even if no xml:lang is set for each topic). Yes that's a bug (but it's ok to me at least xml:lang=zh works...)
Re: Searching Chinese contents doesn't work
Posted: Mon Nov 13, 2023 1:13 pm
by Radu
Hi,
Thanks for confirming this. In general for plain HTML output it's good to add xml:lang to all topics and maps in order to properly translate static texts like for example "Note" derived from DITA <note> elements. Indeed it seems WebHelp output uses the xml:lang set on the map root element and propagates it to be used also for the topics. I did not know this.
Regards,
Radu