Page 1 of 1
detect encoding problem on load
Posted: Thu Dec 13, 2018 10:03 pm
by sderrick
We are using the SDK to provide our editors a way to edit TEI files. Our files are encoded us-ascii.
I just had one of them paste some text in from Word. The text had a few non us-ascii chars, like the curly quote.
If I paste in this text in my desktop oxygen editor and then attempt to save it I get a warning with the location of the offending chars. IN the SDK our editors are not getting this warning , it just saves the file. Then when they try to reopen the file it refuses to open the file because of the encoding error?
How can I fix this?
thanks,
Scott
Re: detect encoding problem on load
Posted: Fri Dec 14, 2018 10:36 am
by Radu
Hi Scott,
So you are using our Author Component Java API to create your own Swing-based Java application, right?
We have API to save the contents ro.sync.exml.workspace.api.editor.WSEditorBase.save(), API which behaves identical with the save operation in the standalone Oxygen version.
Is it possible that you have your own Save operation? Maybe by creating a reader and saving it on disk? Then, you are responsible with the way in which you are encoding the characters to bytes on save. Maybe if you are using "ro.sync.exml.workspace.api.editor.WSEditorBase.createContentReader()" when saving on disk, you should use instead "ro.sync.exml.workspace.api.editor.WSEditorBase.createContentInputStream()" in order for Oxygen to be responsible of the chars to bytes conversion based on the encoding specified in the XML document.
Regards,
Radu
Re: detect encoding problem on load
Posted: Fri Dec 14, 2018 7:31 pm
by sderrick
Radu,
Once again you guys save my bacon. After I started this thread I had the thought that I was probably skipping or doing an end run around the behavior that would catch this for me and you have verified that.
I will follow you advice and let you know how it works.
thanks again for for great tech support,
Scott
Re: detect encoding problem on load
Posted: Fri Dec 14, 2018 8:59 pm
by sderrick
Radu,
I am using editorComponent.getWSEditorAccess().createContentReader() to create a BufferedReader, as you suspected.
Then looping through a read() call on the Reader to build a document text buffer.
Are you saying if I used a createContentInputStream() to get an InputStream, the call would throw an exception if there were bytes in the document that did not conform to the defined encoding? Or the subsequent calls to read() would throw an exception?
Would the exception message specify the character and position information on the problem byte?
thanks,
Scott
Re: detect encoding problem on load
Posted: Sun Dec 16, 2018 3:12 am
by sderrick
I replaced createContentReader() with createContentInputStream()
If I paste in a non ascii char into the editor and then save it, it looks like the bad char is getting replaced by 3 ���. Which are U+FFFD's
This is the behavior the desktop editor does if REPLACE is selected for Encoding error handling. I want it to REPORT, and not replace.
How do I configure the sdk to do that?
thanks,
Scott
Re: detect encoding problem on load
Posted: Tue Dec 18, 2018 12:08 pm
by Radu
Hi Scott,
I will assume you are using the Author Component with the "Text" editing mode as the Author editing mode will automatically escape the character to a character entity if it can not be expressed in the current encoding.
I tested on my side and by default (using the default options) the SDK will throw an exception when the input stream is being read using the "createContentInputStream()" if there is a character which cannot be expressed in bytes using the current encoding.
If it does not throw that exception on your side when reading the reader, you need to look in the fixed set of XML options which you use in the Author Component. There is an options key called "encoding_errors_handling" which may have been set to "1" in your case (meaning replace) instead of "0" meaning report.
Regards,
Radu
Re: detect encoding problem on load
Posted: Tue Dec 18, 2018 10:15 pm
by sderrick
You are correct, the editor is in Text editing mode.
I have not set an option encoding_errors_handling to any value. How would I set it to 0?
We are on version 17.1.0.4, which may be relevant. I haven't upgraded because I normally don;t fix what aint broke.
How much work would you anticipate if I upgrade to the current version of the SDK?
thanks,
Scott
Re: detect encoding problem on load
Posted: Wed Dec 19, 2018 11:00 am
by Radu
Hi Scott,
Please tell me exactly how you saved the XML content before we started having this discussion. Also maybe paste some relevant Java code. Because I have a feeling I do not understand how exactly you were saving the XML before we started having this conversation.
In recent SDK versions (19.1) we also added this method "ro.sync.exml.workspace.api.editor.WSEditorBase.getEncodingForSerialization()" which would have allowed you to create your own OutputStreamWriter and write the content read from our provided Reader.
I have no idea about the implementation effort to move from the 17.1 to the 20.1 SDK, the API is backwards compatible so the move should not be that hard to do.
Regards,
Radu
Re: detect encoding problem on load
Posted: Thu Dec 20, 2018 4:46 am
by sderrick
Radu,
I am using editorComponent.getWSEditorAccess().createContentReader() to create a BufferedReader, then looping through a read() call on the BufferedReader to build a document text buffer.
However....
I just installed the latest Java release 11.0.1 and to my dismay discovered javaws is no longer supported in this and future releases. this is not good for us as we use the jnlp method to execute the sdk applet.
I'm going to delay fixing this issue until we decide how to proceed. I suspect I will explore the use of your Web Author product as a replacement for the SDK applet.
thanks,
Scott Derrick
Re: detect encoding problem on load
Posted: Thu Dec 20, 2018 8:48 am
by Radu
Hi Scott,
Encoding problems occur when converting bytes to characters or characters to bytes.
So using the Reader you read characters and then create some kind of string buffer to hold those characters. The problem comes when serializing those characters to disk. For example if you use a FileWriter to save the characters to disk, the default platform encoding will be used for serialization, on Windows this default platform encoding is usually ISO-8859-1 and on Mac and Linux it is UTF8, in both cases it is not ASCII (which is the encoding specified in the XML document).
So I could do something like this to save to disk obeying the encoding specified in the XML document:
Code: Select all
OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream(file), editor.getEncodingForSerialization());
writer.write(string);
writer.close();
But the method "getEncodingForSerialization" appeared in version 19.1 of the SDK. One option would be to look in the string buffer you have read from the Reader provided by the API and detect the encoding specified in the "<?xml encoding='....'?>" processing instruction located on the first line. Then use that encoding for serialization.
Or I would use the method "ro.sync.exml.workspace.api.editor.WSEditorBase.createContentInputStream()" to read bytes from the input stream and then write them directly to the file output stream.
You can also use Java API directly to check if a particular character can be encoded to a particular charset, something like this:
Code: Select all
java.nio.charset.Charset.forName("ASCII").newEncoder().canEncode(character)
so you could iterate all characters that you are about to save to disk and check if they can be encoded to bytes with a certain encoding.
About the JavaWebStart issue, we'll discuss this on the separate thread you started.
Regards,
Radu
Re: detect encoding problem on load
Posted: Fri Mar 29, 2019 8:46 pm
by sderrick
Radu,
I am using getWSEditorAccess().createContentInputStream(); to get an inputSteam when saving a document.
It is throwing an exception(java.nio.charset.UnmappableCharacterException) when there is a non ASCII character in the document, which is good.
I would like to provide more information as to what the char(s) is and where they are in the document. You folks do that in the stand alone editor.
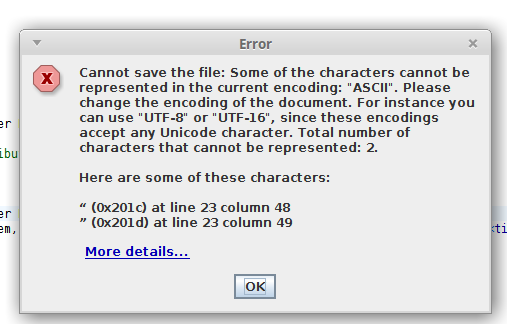
Is there a built in function that does this?
thanks,
Scott
Re: detect encoding problem on load
Posted: Mon Apr 01, 2019 9:40 am
by Radu
Hi,
We do not seem to have a way to throw this error by using the API, I will add an internal issue for this. In the meantime I'm pasting below the code we use to check for unmappable characters before saving:
Code: Select all
private static class UnmappedCharData{
/**
* @param charData The character code
* @param charLine Line in content where the character was found
* @param charColumn Column in content where the character was found
*/
public UnmappedCharData(int charData, int charLine, int charColumn) {
this.charData = charData;
this.charLine = charLine;
this.charColumn = charColumn;
}
/**
* The character data
*/
int charData;
/**
* Line in content where the character was met.
*/
int charLine;
/**
* Column in content where the character was met.
*/
int charColumn;
}
/**
* Check if the characters can be mapped in the current encoding.
*
* @param javaEncoding The java encoding.
* @param defaultEncoding The default encoding.
* @param hasUTF8Bom The bom bytes
* @param contentBuffer The content of the document.
* @throws IOException If the characters cannot be mapped in the current encoding.
* of the encoding is not supported.
*/
private static void checkUnmapedCharacters(WSEditor editor) throws IOException {
try {
// Stream for checking the char range to be in the encoding spec.
OutputStreamWriter testCharsWriter = new OutputStreamWriter(new OutputStream() {
@Override
public void write(int b) throws IOException {
//Not important.
}
}, editor.getEncodingForSerialization());
String effectiveEncoding = testCharsWriter.getEncoding();
int unmapableCharsNo = 0;
Set<UnmappedCharData> firstUnmapableChars = new LinkedHashSet<UnmappedCharData>();
int charLine = 1;
int charCol = 1;
// Check if the characters are mappable if the encoding is different from
// UTF8 or UTF-16
if (!"UTF8".equalsIgnoreCase(effectiveEncoding)
&& !"UTF-16".equalsIgnoreCase(effectiveEncoding)
&& !"UnicodeLittle".equalsIgnoreCase(effectiveEncoding)
&& !"UnicodeBigUnmarked".equalsIgnoreCase(effectiveEncoding)
&& !"UnicodeLittleUnmarked".equalsIgnoreCase(effectiveEncoding)) {
Reader contentBuffer = editor.createContentReader();
char[] buf = new char[10 * 1024];
int readCount = -1;
while((readCount = contentBuffer.read(buf)) != -1) {
for (int i = 0; i < readCount; i++) {
char c = buf[i];
// Check only non ascii characters.
if (c > 127) {
try {
testCharsWriter.write(c);
} catch (UnmappableCharacterException e) {
// The encoding is not good.
if (firstUnmapableChars.size() < 20) {
// Collect only the first 20 characters.
firstUnmapableChars.add(new UnmappedCharData(c, charLine, charCol));
}
unmapableCharsNo++;
}
}
//Increment line/column counters.
if (c == '\n') {
charLine ++;
charCol = 1;
} else {
charCol++;
}
}
}
testCharsWriter.close();
}
if (unmapableCharsNo > 0) {
//TODO show a message here.
}
} catch (UnsupportedEncodingException e) {
throw new IOException(
"Unsupported encoding: " + (editor.getEncodingForSerialization())
+ ". Please change the encoding of the document. "
+ "For instance you can use \"UTF-8\" or \"UTF-16\".");
}
}
Regards,
Radu
Re: detect encoding problem on load
Posted: Mon Apr 01, 2019 5:23 pm
by sderrick
Radu,
thanks, I will put it to good use!

Scott
Re: detect encoding problem on load
Posted: Mon Apr 01, 2019 8:54 pm
by sderrick
Everything worked well except I had to replace
editor.getEncodingForSerialization()
with
Charset.forName(editor.getEncodingForSerialization()).newEncoder()
in the OutputStream constructor.
thanks again,
Scott